条条XPATH通罗马
如果说正则表达式是暴力美学,万物皆可匹配,那么Xpath更像是针对XML文档的一把手术刀,精准的帮你一层层剥开XML文档修饰的外壳,直达元素所在。
XPath(XML Path Language) 是一门在 XML 文档中查找信息的语言。XML 指可扩展标记语言(Extensible Markup Language)。
XML 被设计用来传输和存储数据,不用于表现和展示数据,HTML 则用来表现数据。
但现在也可用于HTML文档的搜索。
下面我们通过python的lxml库,使用Xpath对HTML进行解析
lxml库是第三方库需要进行安装:
1 | pip install lxml |
在使用lxml库时我们这样调用,使用其中的etree模块:
1 | from lxml import etree |
注意在引用etree时编译器可能会表上红色下划线,但其实程序可以正常运行,并不会报错,如果想要解决的话可以这样写:
1 | from lxml import html |
安装完成后我们就可以开始进行XPath的学习了。
XML文档和HTML文档可以看成一颗树,上面有许多的节点,下面给出XPath解析该树的一些常用规则(摘自菜鸟教程)
选取节点
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取(取子节点)。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置(取子孙节点)。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
| 路径表达式 | 结果 |
|---|---|
| bookstore | 选取 bookstore 元素的所有子节点。 |
| /bookstore | 选取根元素 bookstore。注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为 lang 的所有属性。 |
是不是还没开始就感觉很复杂,不用担心,如果你要找的节点不是网页后期JavaScript渲染上去的,那么你可以这样获得其XPath路径:
右键检查
点击圈起来的按钮
鼠标移到想要选中的元素上,单击
鼠标移到网页源码上的阴影区域,右键”复制”,”复制XPath”就可以啦。
当然,现在大部分的网站都会进行JS渲染,很多元素我们都是不能直接在网页源代码里找到的,所以这种方法我们目前还不是很用的到。下面我们正式开始使用XPath解析HTML文档。
1 | <!Doctype html> |
这是菜鸟教程网页的一部分源码,我们想要把他变成可供XPath解析的HTML文档,有以下两种方式:
一.将str类型的text转为HTML
1 | text="<head>......</head>" |
二.将代码存在test.html文件里
1 | htmel=etree.parse('./test.heml',etree.HTMLParser) |
转化完毕之后,我们就需要按上述的规则来解析HTML文档了。
和一般的树一样,HTML节点树的节点之间也有一下几种关系:父节点,子节点,先辈节点,后代节点,我们正是以此为依据来一点一点的解析节点树来获得我们所要的内容的。
所有节点
我们通常使用//来获得所有符合要求的节点,如果我们想要获得所有节点,可以:
1 | result=html.xpath('//*') |
结果:

得到了所有的节点。*代表对节点无限制条件,返回的结果是一个列表,列表里的元素均是Element类型,后面跟着节点的名字。
子节点
子节点或者子孙节点我们可以使用/或//来获得,其中/获得的是当前节点的直接子节点,而//获得的是当前节点的所有子孙结点。例如我们获取第一层的所有子节点:
1 | result=html.xpath('/*') |
结果为:
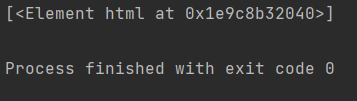
只有一个节点,也就是第一层的html节点。
而使用//*则能获得第一层往下的所有子孙节点,也就是所有的节点。
父节点
想要查找上一层的父节点也很简单,我们可以使用..来完成,
1 | result=html.xpath('//meta[@name="keywords"]') |
这段代码中我们先找了name属性为keywords的meta节点,再寻找他的父亲节点,结果如下;
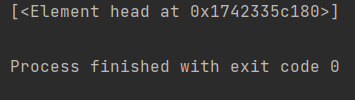
得到了head节点
我们同样可以使用parent::来寻找父亲节点:
1 | result=html.xpath('//meta[@name="keywords"]') |
属性匹配
XPath语法中,采用@来匹配节点的属性值以进行筛选
1 | result=html.xpath('//meta[@name]') |
上述代码筛出了所有含有name属性的meta节点,结果如下

但如果仅仅这样去筛选的话,范围太大了,所以我们需要对具体属性的值进行筛选:
1 | result=html.xpath('//meta[@name="robots"]') |
结果为:
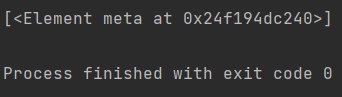
就定位到了

这个meta节点,注意定位时属性值要加上””或’’。
如果你在匹配值是有多个节点属性值相同,那么就不能在使用上面的方法了
文本获取
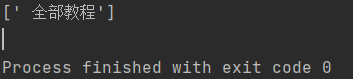
在网络爬虫中,我们往往关注的是标签里的文本内容,例如
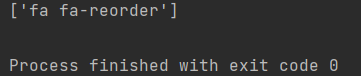
1 | <div class="tab" id="cate0"><i class="fa fa-reorder"></i> 全部教程</div> |
我们想要获取div节点中所夹的”全部教程”四字,可以使用text()方法:
1 | txt=html.xpath('//text()') |
属性获取
属性的获取和属性的匹配其实有点像,只不过少去了[]方括号,
还是用上面的div节点为例,我们要获得i节点的class属性,可以这样:
1 | class_value=html.xpath('//i/@class') |