道高一尺,魔高一丈,再多的反爬手段也拦不住我火热的心(一)
白嫖使我快乐,一切反对和压迫白嫖的都是我们的敌人!!
—— 21世纪伟大的科学家,哲学家 沃兹基.硕德
在之前的博文中我们其实也提到过一些反反爬的手段,例如伪造UA头之类的,本次我们讲更详细的去介绍一些反爬手段和反制它们的方法。

反爬虫简介
使用爬虫虽然对使用者来说是一件很爽很便利的事,但是却令网站维护者,管理员十分头疼,因为爬虫频繁的发起请求会使网站的负担增大,一些个人搭建的小众网站的服务器可能就会因此崩溃,为了减少这些讨人厌的蛀虫,网站的搭建者们也是想尽办法绞尽脑汁用尽各种手段——也就是所谓的反爬手段来防止我们去白嫖网站上的信息。
如果说爬虫是使用任何技术手段,批量获取网站信息的一种方式,那么反爬就是使用任何技术手段,阻止别人批量获取自己网站信息的一种方式。
反爬手段千千万,但大道归一,在高明的反爬手段也不外乎这两种:伪造网站数据和禁止用户请求。我们在平时爬虫时如果不在每次发送请求后sleep上一两秒,就很有可能因IP短时间内请求过频繁的被阻止请求,也就是第二类反爬手段。
对于这些反爬手段,聪明的反爬工作者们也在不断地进步,想出新的办法来应对这些反爬手段,其实爬和反爬只是一念之间,往往会反爬的一定会爬虫,会爬虫的也应定会反爬,只是看他们的工作需要切换角色而已,因此,反爬的防线看似森严,实际上早已漏洞百出,只是"马奇诺防线",在我们掌握了技巧后可以很轻松的绕开,下面我们就正式开始今天的内容。
User-Agent验证反爬
User-Agent反爬虫指的是服务器端通过校验请求头中的User-Agent值来区分正常用户和爬虫程序的手段,这是一种较为初级的反爬虫手段。
User Agent中文名为用户代理,简称 UA。它包含了一个特征字符串,用来让网络协议的对端来识别发起请求的用户代理软件的应用类型、操作系统、软件开发商以及版本号。基本格式如下:
1 | User-Agent: <product> / <product-version> <comment> |
浏览器常用的格式如下:
1 | User-Agent: Mozilla/<version> (<system-information>) <platform> (<platform-details>) <extensions> |
以我们常用的Chorme浏览器为例,在Windows环境下Chorme浏览器的UA头如下:
1 | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 |
- Mozilla/5.0 是一个通用标记符号,用来表示与 Mozilla 兼容,这几乎是现代浏览器的标配。
而如果是爬虫的话,则不会显示这些信息,使用Python中的Requests库向服务器发起HTTP请求时服务器读取的UA是:
1 | python-requests/2.21.0 |
因此要想实现UA反爬的话只需要设置将"python"等关键词加入黑名单,在读取UA时只要发现黑名单上的出现,那么就认为遇到了爬虫,服务器就会阻止此次请求,但这种手段也仅仅只能防住一些练习时长两天半的新手爬虫练习生,而对付那些练习时长两年半的老练习生是远远不够的。
以一个爬虫训练网站为例,这个网站采用了UA反爬:
我们如果直接去请求网页的源代码,并不能得到正确的源码:
1 | import requests |
结果:
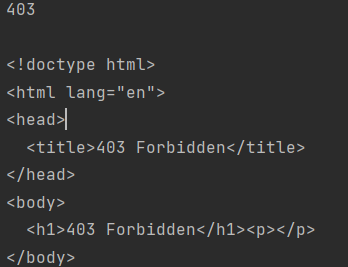
正常如果请求到了网站的源代码,返回的状态码应该是200,而本次请求返回的状态码为403,表示服务器理解请求客户端的请求,但是拒绝执行此请求,更多详细的状态码可以查看菜鸟教程
在这种没有得到正确网页源码的情况下我们最应优先考虑的就是UA反爬,处理UA反爬的方式也很简单,我们只需要伪造一个UA头,随着我们的请求一起发送过去,让服务器以为我们是用浏览器登录的即可。
具体方式如下:
一.从浏览器上复制一个UA
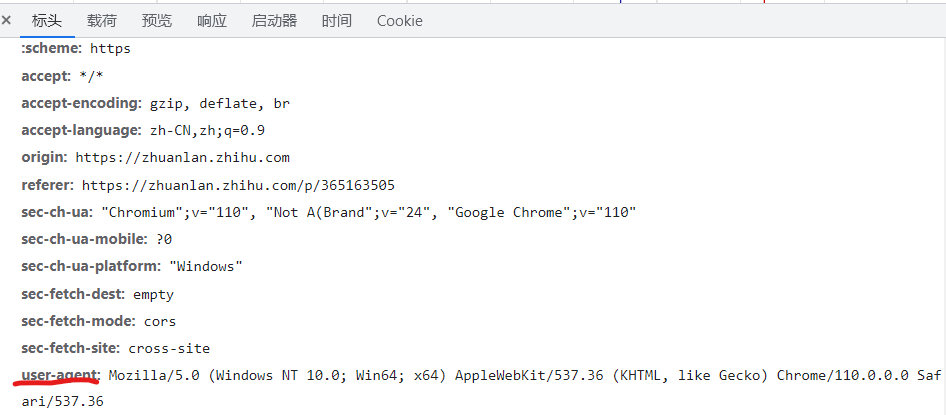
复制下来使用即可,把他添加到请求头里:
1 | import requests |
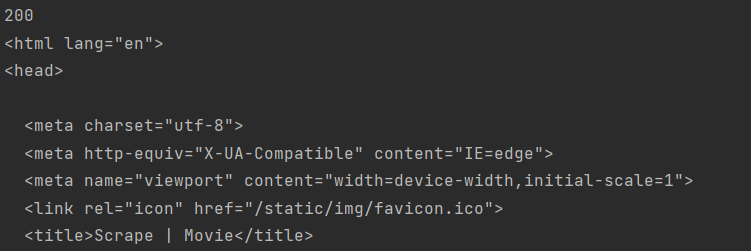
我们发现请求就能正常通过了,也能正常获得网页源码。
二.用fake_useragent库伪造一个
fake_useragent库,库如其名,是专门用来造假的user-agent的,它使用起来也很简单:
1 | import requests |
先构造一个UserAgent对象,在随便从里面选一个使用即可
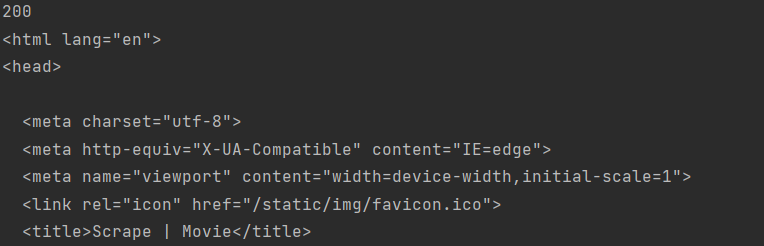
也是能获得到正确的网页源代码。
重定向反爬
重定向是一个很广泛的概念,即通过各种方法将各种网络请求重新定个方向转到其它位置,比如网页重定向、域名重定向、数据报文重定向等。
在我们日常学习工作时,也常常会遇到这样的情况:看到一个好的网站,把它保存了下来,结果下一次点进去的时候却跳转到别的地方去了,这就是遇到了重定向,网站的维护者希望你是从它的主页进去的,而不希望你直接进入,所以你在请求此网页时,他会检测你前一个网站的信息,如果是首页的信息,他就允许你的请求,反之则拒绝,我们直接看一个例子:
这是一个爬虫练习的网站:
第一个挑战是UA与referer校验反爬,Referer就是上一个页面的地址,这个是浏览器会在点击一个链接时自动添加到请求头中的,UA反爬怎么处理我们已经讲过了,我们就着重来看看后面的referer校验反爬:
我们打开第一关:
尝试爬取一下他的数据:
1 | import requests |
结果是:
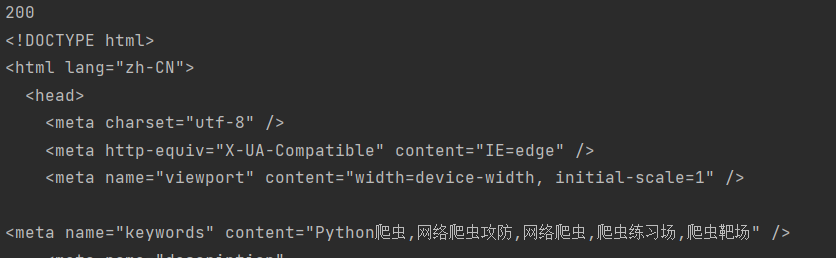
我们发现状态码是200,说明我们的请求成功了,但得到的源代码却不太对,仔细一看,这不是训练场首页的源代码吗,
我们尝试直接打开一下它的链接,发现直接调到了网站首页,这时候我们就知道是遇上重定向了,这时候我们看一下两次网站的请求有什么区别:
直接进入链接:
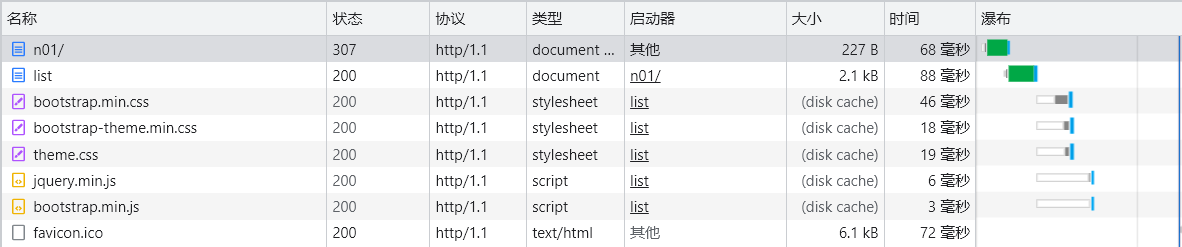
从首页进入的:

我们注意到直接进入是有一个名为"n01/"的请求状态码为307,我们查询的307是临时重定向,与302类似,使用GET请求重定向,
那么我们该怎么解决重定向问题呢,答案也很简单,他需要什么,我们就给他什么,他想让我们先进入首页,我们不妨伪造信息让他以为我们进入过首页,我们比较一下两次"n01/"请求的请求头文件:
直接进入链接:
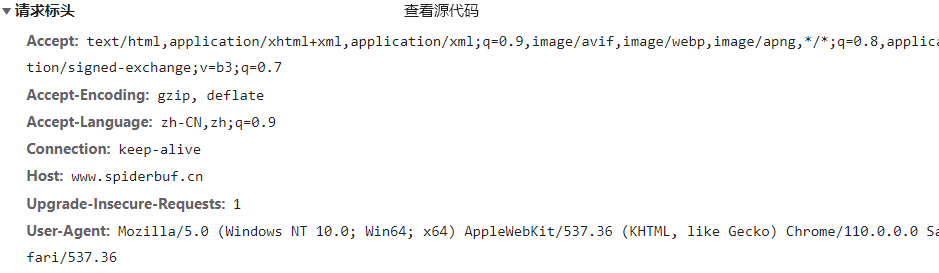
从首页进入的:
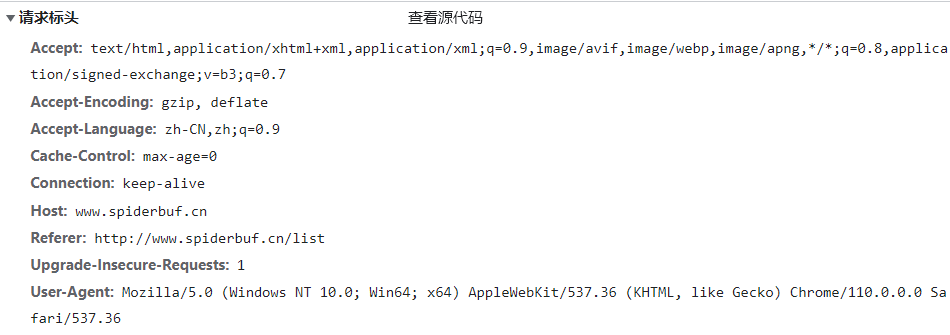
发现请求成功的请求头里多了一个referer参数,这正是前一个网站的网址,那么我们在请求的时候,也只要加上这个参数给他发送过去就行了,话不多说,我们动手试一试:
1 | import requests |
结果如下:

正是目标网站的源代码,说明我们这次是彻彻底底的是成功了。