第一次爬虫实战。
我们先随便在网上找一个能免费看小说的网站:
https://www.biquke.vip/
点击一本书打开:
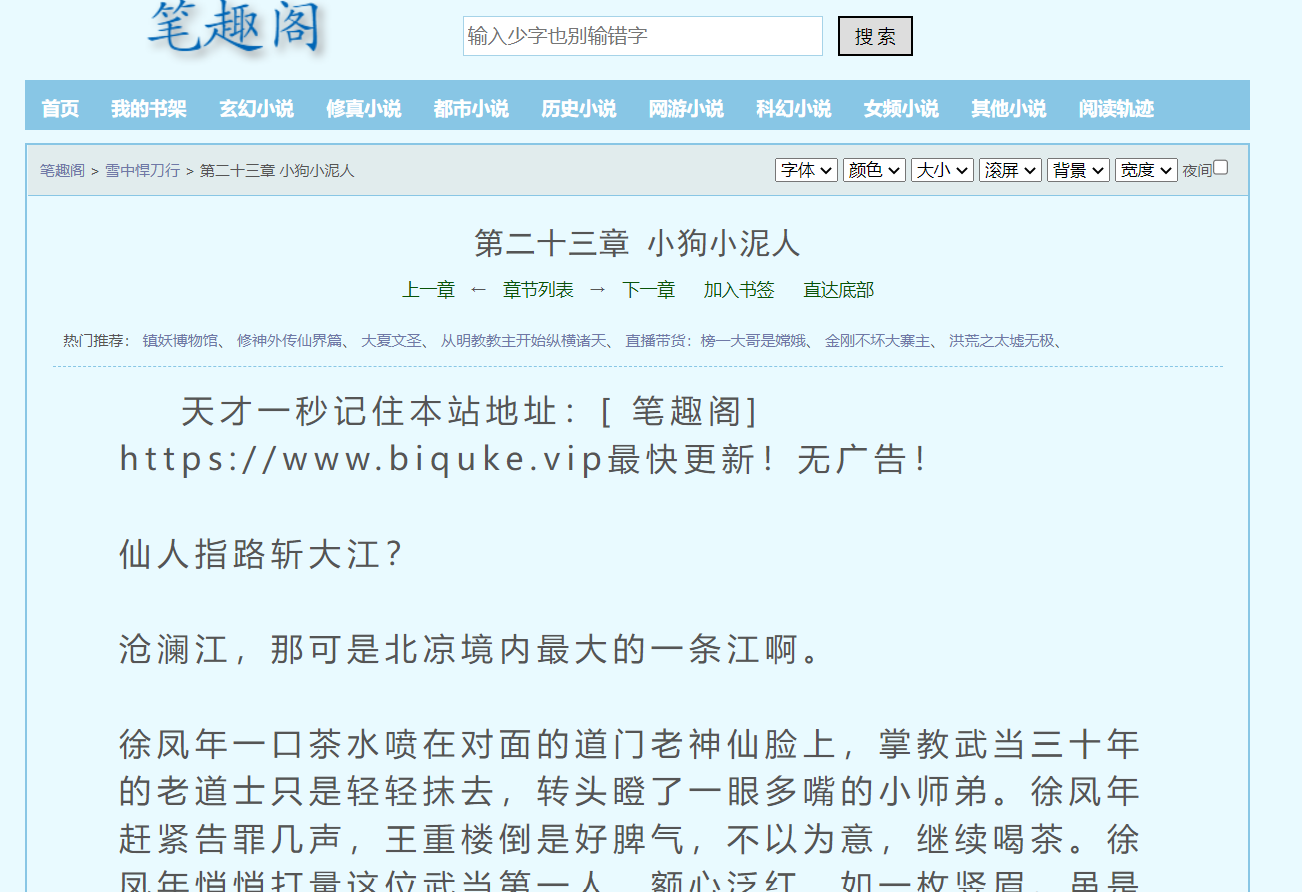
随便挑一章进入:
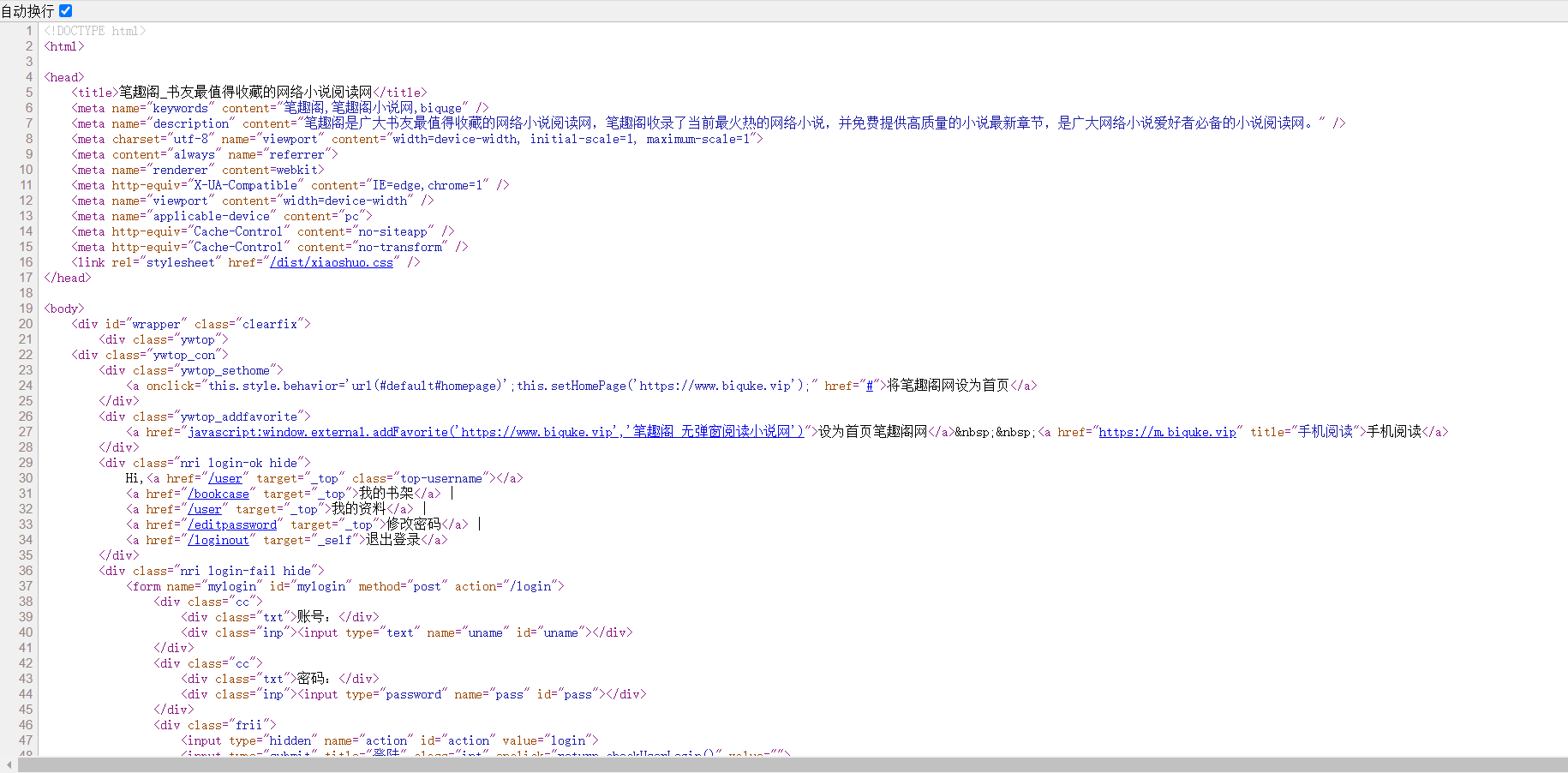
鼠标右键查看网页源代码:
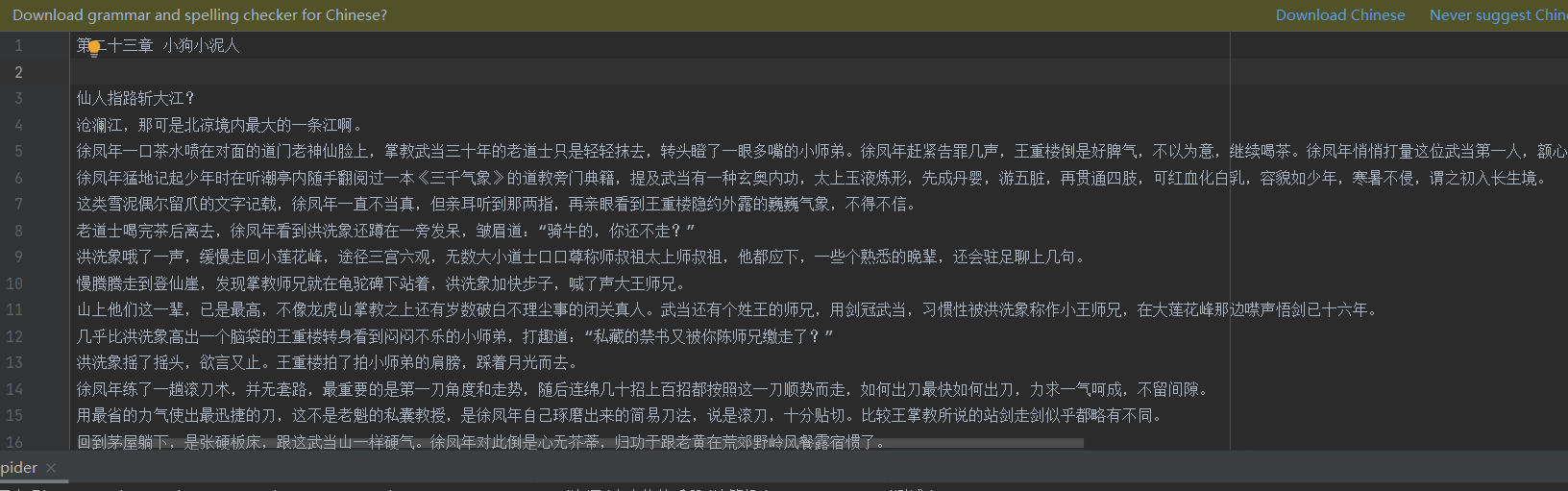
我们先获取这一章的标题,Ctrl+F搜索小狗小泥人 ,发现有九个之多,我们随便选一个:
再来看文本内容,搜索仙人指路 ,发现文本的内容都在一起,且格式十分的统一。
在知道了这些内容后我们就可以进行该章节的爬取了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 from bs4 import BeautifulSoupimport requestsimport sysimport ioimport osimport timesys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030' ) url="https://www.biquke.vip/book/204/137492.html" resp=requests.get(url) 设置解码格式为"utf-8" resp.encoding="utf-8" 创建beautifulsoup对象 main_page=BeautifulSoup(resp.text,"html.parser" ) text_name=main_page.find("div" ,class_="bookname" ).find("h1" ).get_text().strip() texts=[text_tag.get_text().strip() for text_tag in main_page.find_all('p' ,class_="content_detail" )] with open (f"{text_name} .txt" ,mode='w' ) as f: f.write(f"{text_name} \n\n" ) for text in texts: f.write(text+'\n' )
结果如下:
我们成功的把这一章的内容爬取下来了!!
但是
我们的目标可不仅仅是小说的某一个章节,是整本小说,甚至更进一步爬取别的小说,一次我们就需要进行更深一步的分析:
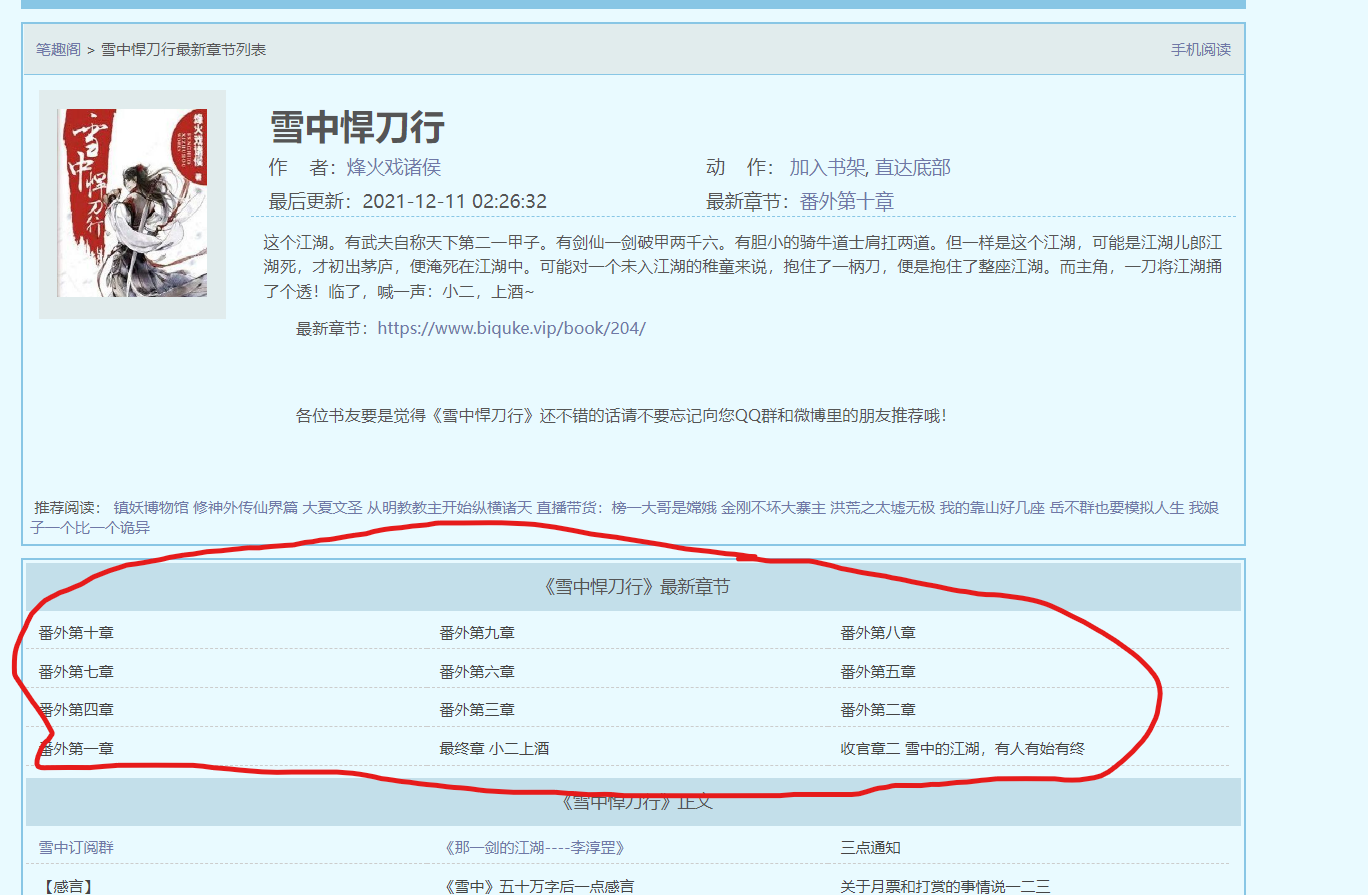
我们先回到书的主界面,右键查看网页源代码,先分析我们需要什么,我们想要每一章的地址,这样我们就可以一章一章的爬取下来了,Ctrl+F搜索第一章 ,这个可能因为网站的原因,章节的编号有一点乱,但不影响。
注意到第一章 小二上酒 的上面有一个href=”/book/204/137470.html” ,我们打开第一章对比一下:
刚好就是第一章网址的后面部分,大家可以再对比几章,都是一样的结果,而且都是在<dd>标签下的<a>标签里,但是
我们注意到
它还有一个最新章节的东西,而且里面的章节下面也有,所以我们在搜索的时候,需要做一些限定。
我们可以把上面爬取一章内容的代码封装成一个函数。
完整代码附上:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 from bs4 import BeautifulSoupimport requestsimport sysimport ioimport osimport timesys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030' ) url="https://www.biquke.vip/book/204/137492.html" def get_novel_text (url ): resp=requests.get(url) resp.encoding="utf-8" main_page=BeautifulSoup(resp.text,"html.parser" ) text_name=main_page.find("div" ,class_="bookname" ).find("h1" ).get_text().strip() texts=[text_tag.get_text().strip() for text_tag in main_page.find_all('p' ,class_="content_detail" )] with open (f"{text_name} .txt" ,mode='w' ) as f: f.write(f"{text_name} \n\n" ) for text in texts: f.write(text+'\n' ) f.close() print (f"{text_name} 下载完毕" ) def main (): main_url="https://www.biquke.vip/book/204/" main_resp=requests.get(main_url) main_page=BeautifulSoup(main_resp.text,"html.parser" ) urls=[tag.find('a' ).get("href" ) for tag in main_page.find_all("dd" )[12 :]] for url in urls: get_novel_text("https://www.biquke.vip" +url) time.sleep(0.5 ) if __name__ =="__main__" : main()
就可以愉快的下载整本书阅读了!!,本程序还有很多细节可以优化——添加输入想要下载小说名字的功能,新建一个文件夹存放小说,过滤掉一些没有正文内容的章节,使用多线程加速下载…..感觉兴趣的话可以自己尝试。那么本篇内容就到此结束了,感谢各位的观看Thanks♪(・ω・)ノ。