python爬虫之re模块
python爬虫之re模块
本文介绍如何通过python的re模块对网页文本进行解析,获得你想要的内容。
一.正则表达式
(一)定义
正则表达式,又称规则表达式,(Regular Expression,在代码中常简写为regex、regexp或RE),是一种文本模式,可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
(二)语法
在线正则表达式测试网站:https://c.runoob.com/front-end/854/
https://tool.oschina.net/regex/
我们简单列出一些正则表达式的语法
| 字符 | 描述 |
|---|---|
| [ABC] | 匹配[…]中的所有字符,如[aeiou]匹配所有的元音字母; |
| ABC | 匹配除[…]中字符的所有字符; |
| [A-Z] | [A-Z]表示一个区间,比配所有大写字母,[a-z]表示所有小写字母 |
| . | 比配除换行符之外的任何单个字符 |
更多具体的可参考https://www.runoob.com/regexp/regexp-syntax.html
在爬虫中,我们使用最多的是一种”贪婪匹配”:.*和.*?。
1.*和+限定符是贪婪的,会尽可能多的匹配字符,例如<.*>会匹配文本中从第一个<到最后一个>中包括的所有内容,如用<.*>匹配<h1>zhulizhe<h1>的结果就是<h1 >zhulizhe<h1>。
2.我们通过在*,+后面加上?,可以使该表达式从”贪婪”表达式转换为”非贪婪”表达式或者最小匹配。例如<.*?>匹配所有最小的<>中的内容,如用<.*?>匹配<h1>zhulizhe<h2>结果有两个:<h1>和<h2>。
通过各种语法的组合正则表达式还能进行很多有意思的匹配,但在这里就不过多介绍了。
二.re模块
re模块是python独有的利用正则表达式匹配字符串的模块,re模块是一个自带的第三方库,并不需要你额外下载,只需要在开头加上:
1 | import re |
调用即可。
本文对re模块不做过多介绍,着重介绍爬虫最常用的re.complie函数
re.comple函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,语法格式是:
1 | re.compile(pattern[,flags]) |
参数:
- pattern : 一个字符串形式的正则表达式
- flags 可选,表示匹配模式,常见的有:
| 修饰符 | 描 述 |
|---|---|
re.I |
使匹配对大小写不敏感 |
re.L |
做本地化识别(locale-aware)匹配 |
re.M |
多行匹配,影响 ^ 和 $ |
re.S |
使。匹配包括换行符在内的所有字符 |
re.U |
根据 Unicode 字符集解析字符。这个标志影响 \w、\W、\b 和 \B |
re.X |
该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解 |
我们通常选择模式为re.S,为了防止字符串中的转义字符,我们通常使用r”………”的形式,这个r代表了原字符串的意思,可以省略转义字符。
特殊的,我们在patten中通常还会使用解析结构式 (?P
下面我们正式在python爬虫中试用一下compile函数。
三.re爬虫实战

我们想要获取百度主页的百度热搜信息,右键查看网页源代码,Crtl+F搜索卫星视角下的祖国大地有多美

发现有两处,且其他的热搜内容也都在,我们任选一处就行获取就行。我们观察一下这几处热搜内容的特征,发现内容的前面都有“title-content-title”>,后面都有</span>且搜索后有且仅有这几处有,我们就可以通过它来定位,匹配的代码就可以这样写:
1 | obj=re.compile(r"\"title-content-title\">(?P<resou>.*?)</span>",re.S) #\表示转义" |
在这里我们在介绍re的两个函数findall和finditer,findall将匹配到的所有内容打包成列表的形式返回而finditer则返回一个迭代器。我们在这里选择使用finditer函数:
1 | result=obj.findall(page_content) |
如果想要遍历迭代器并打印内容可以这样:
1 | for it in result: |
打印结果为:
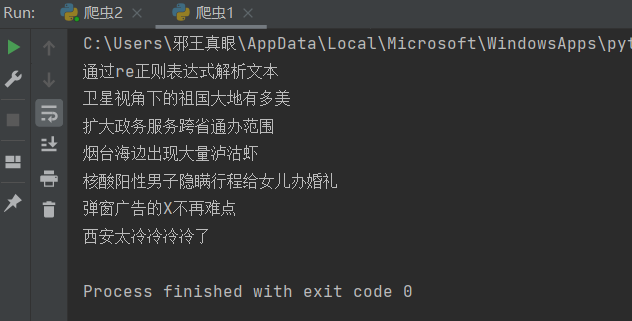
下面附上完整代码:
1 | import requests #导入requests库 |
本文到此就结束了,感谢支持ღ( ´・ᴗ・` )。